
Essa semana precisei construir uma pipeline de agregação no MongoDB com um objetivo pouco usual: precisava de um estágio de lookup onde o parâmetro from fosse condicional, do tipo: se o valor do campo X for A, pesquise em uma dada collection, se for B, pesquise em outra.
Pense num cenário onde um dado campo do documento armazena um ObjectId que pode ser uma referência a documentos de duas ou mais collections, como uma chave de entidade. Se for preciso buscar o documento dela, como fazer isso numa mesma pipeline e sem perder performance?
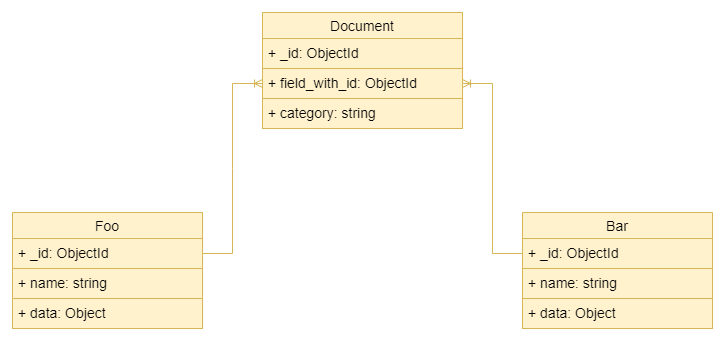 Uma relação one-to-many em que um campo da entidade poderia conter relação com uma ou outra entidade
Uma relação one-to-many em que um campo da entidade poderia conter relação com uma ou outra entidade
Pensando em um banco relacional, provavelmente a melhor opção seria fazer duas seleções separadas, em que cada uma filtraria pelo valor do campo X correspondente e faria o join com a tabela correta, e depois uni-las com UNION. Mas, como seria o modo NoSQL de conseguir esse tipo de informação?
Bem, o desafio foi esse.
No começo pensei em coisas como fazer um from condicional:
1
2
3
4
5
6
7
8
9
'from': {
'$cond': {
'if': {
'$eq': ['$field', 'A']
},
'then': '<uma collection>',
'else': '<outra collection>'
}
}
Claro que deu errado, o parse do mongo avaliou como objeto em vez de avaliar a expressão e acusou um erro de tipo, pois esperava receber uma string. E faz sentido.
Então voltei a pensar em como resolveria isso usando SQL - dois selects e uma união - e, trazendo o conceito para o paradigma não relacional, cheguei à pipeline abaixo. É um exemplo fictício. Primeiro, algumas considerações:
- Estou usando a versão 4.4 do MongoDB, que ainda não suporta a sintaxe concisa para subconsultas no lookup;
- No exemplo, o campo
field_with_idcontém o ObjectId que preciso buscar em duas collections diferentes -fooebar; - O campo
categorycontém um dado categórico que me ajuda a descobrir em qual collection vou encontrar o id emfield_with_id; - Os campos
nameedatasão aqueles que eu quero no objeto buscado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
[
{
'$lookup': {
'from': 'foo',
'let': {
'idToLookup': '$field_with_id',
},
'pipeline': [
{
'$match': {
'$expr': {
'$eq': ['$_id', '$$idToLookup']
}
}
},
{
'$project': {
'name': 1,
'data': 1
}
}
],
'as': 'foo_obj'
}
},
{
'$lookup': {
'from': 'bar',
'let': {
'idToLookup': '$field_with_id',
},
'pipeline': [
{
'$match': {
'$expr': {
'$eq': ['$_id', '$$idToLookup']
}
}
},
{
'$project': {
'name': 1,
'data': 1
}
}
],
'as': 'bar_obj'
}
},
{
'$addFields': {
'foo_obj': {
'$arrayElemAt': ['$foo_obj', 0]
},
'bar_obj': {
'$arrayElemAt': ['$bar_obj', 0]
}
}
},
{
'$project': {
'fielda': 1,
'fieldb': 1,
'fieldc': 1,
'searched_obj': {
'$switch': {
'branches': [
{
'case': {
'$eq': [
'$category', 'A'
]
},
'then': '$foo_obj'
},
{
'case': {
'$eq': [
'$category', 'B'
]
},
'then': '$bar_obj'
}
],
'default': null
}
}
}
}
]
Parece grande, mas na prática são apenas 3 estágios essenciais. A ideia foi executar dois lookups, um para cada collection, e depois usar o switch pra escolher qual objeto seria considerado de acordo com o campo category. O estágio addFields aqui serve apenas para pegar do array o primeiro - e neste caso único - objeto retornado pela pesquisa. Estou usando a sintaxe com subconsulta no lookup para já trazer apenas os campos de interesse name e data e evitar desperdício de memória (um benefício talvez quase nulo a depender da situação, mas é uma boa prática).
No começo, cheirava a gambiarra, mas depois vi que performou muito bem, tendo um aumento de cerca de apenas 10% no tempo de processamento total (não apenas do banco de dados, considerando latência etc.). Logo percebi que era justamente o modo não relacional de fazer esse tipo de consulta.
Claro que uma modelagem dos dados pensada para essa finalidade desde a concepção poderia considerar a incorporação dos campos de interesse em cada documento, o que evitaria a necessidade de junções. Mas não foi esse o caso.
Uma ressalva importante aqui é que essa consulta funcionou muito bem para o problema que tinha, que envolvia num estágio anterior um belo filtro que fazia com que a quantidade de documentos a essa altura do pipeline fosse já drasticamente reduzida. A performance desse tipo de consulta vai variar para cada aplicação e também deve considerar a existência de índices. Se você for buscar algo diferente da chave primária ou fazer consultas com correspondências compostas, considere ajustar índices para garantir uma boa performance.
É isso.